*该笔记是整理和总结项目中遇到的一些oracle使用时的坑 *
一、Oracle语法坑
(一)union和union all大坑
union all 和union 都是两个子查询结果集做拼接,但是union会自动去重。union all是全连接,不去重。
union all实例:
select 'tom' name, '22' age
from dual
union all
select 'tom' name, '22' age
from dual查询结果:全连接,不自动去重
| name | age |
|---|---|
| tom | 22 |
| tom | 22 |
union实例
select 'tom' name, '22' age
from dual
union
select 'tom' name, '22' age
from dual
查询结果:会自动去重,只返回一条
| name | age |
|---|---|
| tom | 22 |
(二)union all顺序和结果
union all 会以第一个查询结果顺序为主,如果union all后面顺序和第一个子查询顺序不一致,后面查询顺序会以第一个的顺序返回结果,不会调整。
正确实例:
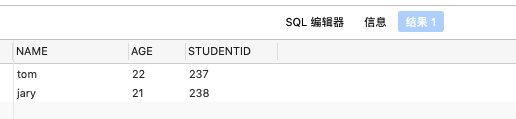
select 'tom' name, '22' age,'237' StudentID
from dual
union all
select 'jary' name, '21' age,'238' StudentID
from dual查询结果:
| name | age | ID |
| —- | —- |—-|
| tom | 22 |237 |
| jary | 21 |238 |
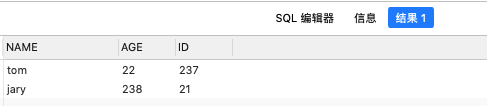
错误实例:
第一个子查询字段顺序 name、age、ID,第二个子查询字段顺序name 、ID、age,当union all的时候,会按照第一个子查询的字段顺序进行拼接返回。
select 'tom' name, '22' age,'237' ID
from dual
union all
select 'jary' name, '238' ID ,'21' age
from dual查询结果
| name | age | ID |
| —- | —- |—-|
| tom | 22 |237 |
| jary | 238 |21 |
二、oracle锁表和解锁
(一) ORACLE中查看当前系统中锁表情况
select * from v$locked_object 可以通过查询v$locked_object拿到sid和objectid,然后用sid和v$session链表查询是哪里锁的表,用v$session中的objectid字段和dba_objects的id字段关联,查询详细的锁表情况。
select sess.sid,
sess.serial#,
lo.oracle_username,
lo.os_user_name,
ao.object_name,
lo.locked_mode
from v$locked_object lo, dba_objects ao, v$session sess, v$process p
where ao.object_id = lo.object_id
and lo.session_id = sess.sid;(二)查询是什么SQL引起了锁表的原因,SQL如下:
select l.session_id sid,
s.serial#,
l.locked_mode,
l.oracle_username,
s.user#,
l.os_user_name,
s.machine,
s.terminal,
a.sql_text,
a.action
from v$sqlarea a, v$session s, v$locked_object l
where l.session_id = s.sid
and s.prev_sql_addr = a.address
order by sid, s.serial#;(三)ORACLE解锁的方法
alter system kill session 'sid, s.serial#'; –146为锁住的进程号,即spid三、表分析
问题场景:
项目对一张表1.3亿数据,增加了表字段默认值0,上线后,该表查询非常慢,查看执行计划,没有走索引,跑偏了,后来经对表进行了表分析后,表查询开始走索引。
当大表数据量变化超过10%时,建议做表分析,重新收集统计信息
(一)Oracle分析表的作用:
为了使基于CBO的执行计划更加准确,分析的结果被Oracle用于基于成本的优化生成更好的查询计划。
(二)表分析语法
SQLPLUS语法
analyze table tablename compute statistics
等同于
analyze table tablename compute statistics for table for all indexes for all columnsSQL语法
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(ownname => 'user',--用户名
tabname => 'tablemane',--表名称
cascade => TRUE,
estimate_percent => 10,--segment采样比例,建议5-20
no_invalidate => FALSE,--立马生效
degree => 8,--并行度
granularity => 'ALL'--分区表用,非分区表可删除
);
END;
/DBMS_STATS.GATHER_TABLE_STATS语法参数说明
参数说明:
ownname:要分析表的拥有者
tabname:要分析的表名.
partname:分区的名字,只对分区表或分区索引有用.
estimate_percent:采样行的百分比,取值范围[0.000001,100],null为全部分析,不采样. 常量:DBMS_STATS.AUTO_SAMPLE_SIZE是默认值,由oracle决定最佳取采样值.
block_sapmple:是否用块采样代替行采样.
method_opt:决定histograms信息是怎样被统计的.method_opt的取值如下(默认值为FOR ALL COLUMNS SIZE AUTO):
for all columns:统计所有列 的histograms.
for all indexed columns:统计所有indexed列的histograms.
for all hidden columns:统计你看不到列的histograms
for columns <list> SIZE <N> | REPEAT | AUTO | SKEWONLY:统计指定列的histograms.N的取值范围[1,254]; REPEAT上次统计过的histograms;AUTO由oracle决定N的大小;SKEWONLY 选项会耗费大量处理时间,因为它要检查每个索引中的每个列的值的分布情况。
degree:决定并行度.默认值为null.
granularity:Granularity of statistics to collect ,only pertinent if the table is partitioned.
cascade:是收集索引的信息.默认为FALSE.
stattab:指定要存储统计信息的表,statid如果多个表的统计信息存储在同一个stattab中用于进行区分.statown存储统计信息表的拥有者.以上三个参数若不指定,统计信息会直接更新到数据字典.
no_invalidate: Does not invalidate the dependent cursors if set to TRUE. The procedure invalidates the dependent cursors immediately if set to FALSE.
force:即使表锁住了也收集统计信息.四、并行PARALLEL和nologging使用
问题场景:
生产表为了提高查询效率,需要对一个字段增加索引,该表数据量1.5亿左右,演练时增加索引执行了15分钟,两个字段联合索引执行了28分钟,所有人沙雕了…后面还有几个索引要加。。。投产窗口总共1个小时,肯定不够
解决方案:
添加索引时开并行,关日志 原来15分钟的执行变成了2分钟左右,效果显著
SQL语法
1. 使用PARALLEL 开并行 和 NOLOGGING关闭日志
create index 索引名 on 表名称 (列名称) PARALLEL 16 NOLOGGING tablespace 索引空间 ;
生产实例:
create index IDX_索引名 on 表名称 (字段名) PARALLEL 16 NOLOGGING tablespace INDEXSPACE ;2. 执行后需要将索引并行度还原
ALTER INDEX 索引名 PARALLEL 1;
生产实例:
ALTER INDEX IDX_索引名 PARALLEL 1;nologging小结
nologging不能执行DML语句,不生效。
nologging对以下生效:
direct load (SQL*Loader);
direct load INSERT (using APPEND hint);
CREATE TABLE … AS SELECT;
CREATE INDEX ;
ALTER TABLE … MOVE PARTITION ;
ALTER TABLE … SPLIT PARTITION ;
ALTER INDEX … SPLIT PARTITION ;
ALTER INDEX … REBUILD ;
ALTER INDEX … REBUILD PARTITION ;
INSERT, UPDATE, and DELETE on LOBs in NOCACHE NOLOGGING mode stored out of line ;五、开发过程中insert使用
insert into base_bank
values
(#bankid#,#bankname#) 开发过程中,有些开发人员习惯这样写,将这种SQL写到项目中,语法上虽然没有错误,但是,当表增加了字段,这段SQL在程序执行过程中就会报错,因为values没有足够的值。这样为后面的开发人员和项目维护埋了一个很大的雷。
因此推荐insert具体字段,如下
insert into base_bank
(bankid,bankname)
values
(#bankid#,#bankname#)生产实例,炸断两条腿的雷
<statement id="updateTradelogForMCIS" parameterClass="tradelog">
MERGE INTO CORP_RICH_REDEEMORDERTRADE S
USING (select #relSerialno# as SERIALNO from dual) C
ON (S.SERIALNO = C.SERIALNO)
WHEN MATCHED THEN
UPDATE SET S.REDEMPTIONDATE = #redemptionDate#
WHEN NOT MATCHED THEN
INSERT
VALUES
(C.SERIALNO,
#issueid#,
#account#,
#custAccount#,
#currencyId#,
#buymode#,
#cashAmount#,
#billAmount#,
#cashUnit#,
#billUnit#,
#bankid#,
#trancode#,
#orderDate#,
#execDate#,
#state#,
#payMode#,
#teller#,
#operatorid#,
#operatorName#,
#operatorDate#,
#checkid#,
#checkName#,
#checkDate#,
#authid#,
#authName#,
#authDate#,
#tradeChannel#,
#cancelDate#,
#cancelId#,
#cancelName#,
#memo#,
#startDate#,
#maturityDate#,
#totalPeriods#,
#benchmark#,
#redemptionDate#,
#custProductBalInfoId#,
#attr#,
#isSpecialTrade#,
#orderRedPeriod#,
0,
#channelSerialno#)
</statement> 上述SQL看着一切正常,在项目上线时也没啥问题,可是后面项目升级时,表CORP_RICH_REDEEMORDERTRADE增加了一个字段Fee,该字段是个默认值为0的字段,当时开发评估,既然默认值为0,我只需要在我需要的地方插入值就可以,其他业务需要这张表的地方就没改,结果引发了一场血案,影响业务使用
六、谁动了我的数据库
背景测试小姐姐告诉我,他们库里面一张表没了。。。。what?没了?ghost?,开启名侦探模式…
(一) drop表恢复
查看回收站是否存在
select S.*
from user_recyclebin s
where s.original_name = 'RICH_CUSTOMERINFO';
或者
select * from recyclebin t order by t.droptime desc;执行表恢复
flashback table tableName to before drop --可选择参数[ rename to newTableName];(二)delete表数据恢复
1. 根据scn闪回
查询scn(system change number)号
select dbms_flashback.get_system_change_number from dual;根据scn查询对应表数据是否满足回滚条件
select * from tableName as of scn 13102359953430;根据scn闪回数据
flashback table tableName to scn 13102359953430;2. 根据时间恢复
查询当前电脑时间
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss')from dual;查询删除之前的数据
select * from EMP as of timestamp to_timestamp('2018-04-12 09:12:11','yyyy-mm-dd hh24:mi:ss');闪回数据
flashback table EMP to timestamp to_timestamp('2018-04-12 09:12:11','yyyy-mm-dd hh24:mi:ss');如果出现报错:ORA-08189:未启用行移动功能,不能闪回表
alter table EMP enable row movement;(三)生产实操drop表恢复
1. 检查回收站表还在不在(oracle10G以上)
select S.*
from user_recyclebin s
where s.original_name = 'RICH_CUSTOMERINFO';
看一下这一天都删了什么。。
select S.*
from user_recyclebin s
where trunc(to_date(s.droptime,'yyyy-mm-dd HH24:mi:ss'))
= to_date('20190730','yyyymmdd')
and s.type ='TABLE';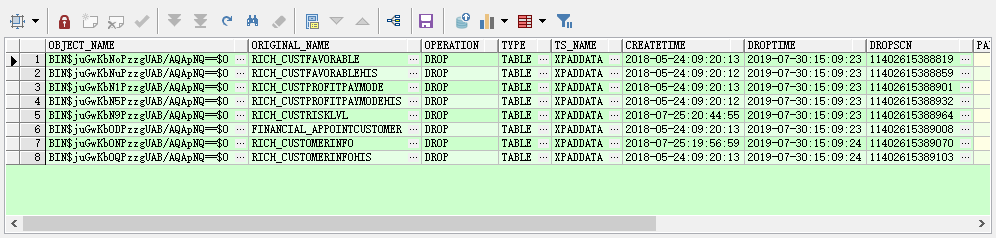
2. 执行表的恢复
赶紧先给小姐姐把表数据恢复了,辛辛苦苦造的数据…
flashback table tablename to before drop;用脚本生成所有的sql恢复脚本:
select 'flashback table ' || S.original_name || ' to before drop;'
from user_recyclebin s
where trunc(to_date(s.droptime, 'yyyy-mm-dd HH24:mi:ss')) =
to_date('20190730', 'yyyymmdd')
and s.type = 'TABLE';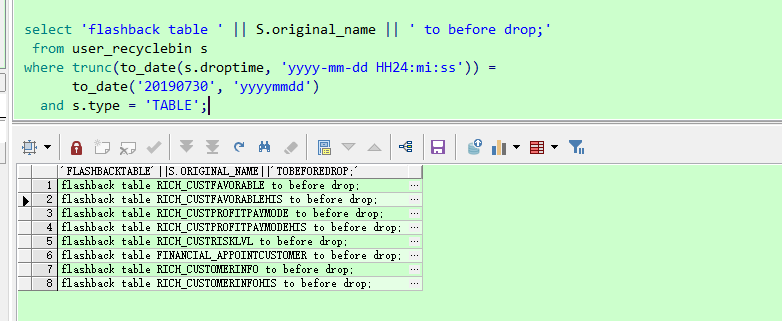
执行脚本:
flashback table RICH_CUSTFAVORABLE to before drop;
flashback table RICH_CUSTFAVORABLEHIS to before drop;
flashback table RICH_CUSTPROFITPAYMODE to before drop;
flashback table RICH_CUSTPROFITPAYMODEHIS to before drop;
flashback table RICH_CUSTRISKLVL to before drop;
flashback table FINANCIAL_APPOINTCUSTOMER to before drop;
flashback table RICH_CUSTOMERINFO to before drop;
flashback table RICH_CUSTOMERINFOHIS to before drop;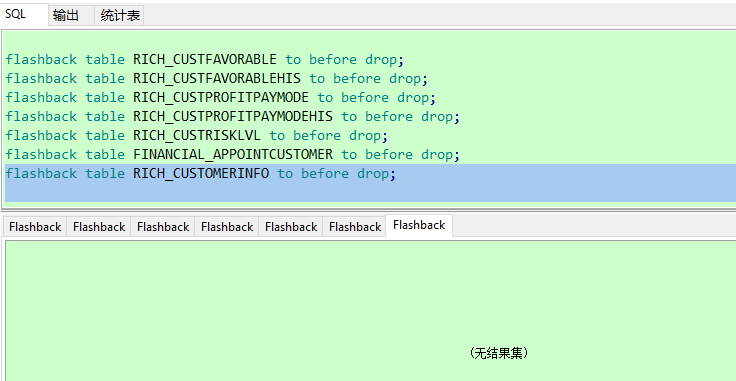
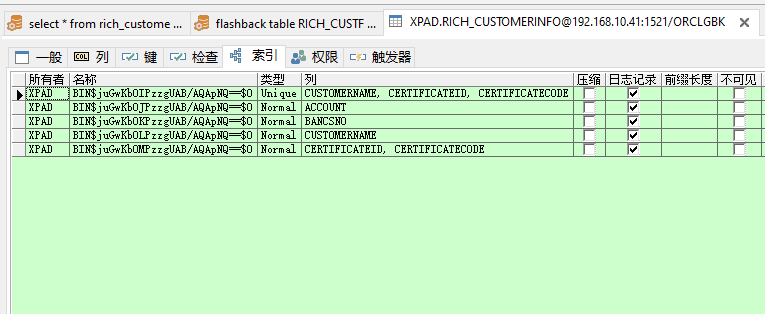
查询数据还在,索引也回来了: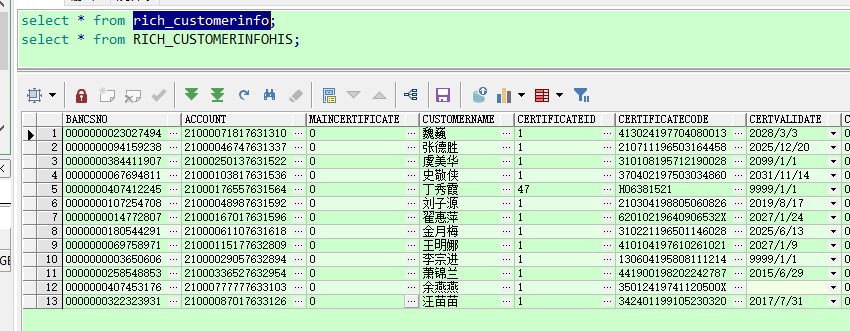
查询SQL执行历史
select t.FIRST_LOAD_TIME, t.*
from v$sqlarea t
where t.PARSING_SCHEMA_NAME in ('XPAD')
and t.sql_text like '%DROP%'
order by t.LAST_ACTIVE_TIME desc;



